EPC Solar Data 데이터 생성부터 모델링(feat.AI 공부)
※ 글을 복사해서 쓰고싶으면
제가 쓴 꿀팁글 중 '복사안되는블로그 이제는 할 수 있읍니다.'
글을 참고하시면 복사해서 쓸 수 있읍니다.
EPC Solar Data가 필요하여 찾아봤더니 데이터자체를 구하기 너무 어려웠읍니다.
그래서 실제 필리핀 기후환경을 토대로 데이터 자체를 만들고 전처리와 EDA Modeling 까지 해보았읍니다.
(이 글은 EPC Solar데이터가 필요하여 데이터 생성부터 모델링까지를 다루었지만,
인공지능을 처음 공부해보는 사람도 충분히 많은 공부가 될 것 입니다.)
Github 주소에 파일 전체에 대해 업로드해놨읍니다.
github : https://github.com/qazxcv3323/EPC_Solar_System
GitHub - qazxcv3323/EPC_Solar_System
Contribute to qazxcv3323/EPC_Solar_System development by creating an account on GitHub.
github.com
링크를 클릭하여 ZIP 파일로 다운받거나 git clone 을이용하여 다운받아주시면 될 것 같읍니다.
Readme.md 파일을 보시고
data generate -> EDA -> modeling -> Best Model visualization 에 대해 분석해보시기 바랍니다.
--------------------------------------- Readme.md ---------------------------------------
# EPC Solar System Defect Check Classification And EDA
## EPC_Solar_System_AI_Anlyasis
#### data generate -> EDA -> modeling -> Best Model visualization
## 프로세스 흐름
## File Description
# 개요
## 결론
--------------------------------------- Readme.md ---------------------------------------
필요한 라이브러리 Import

데이터 생성
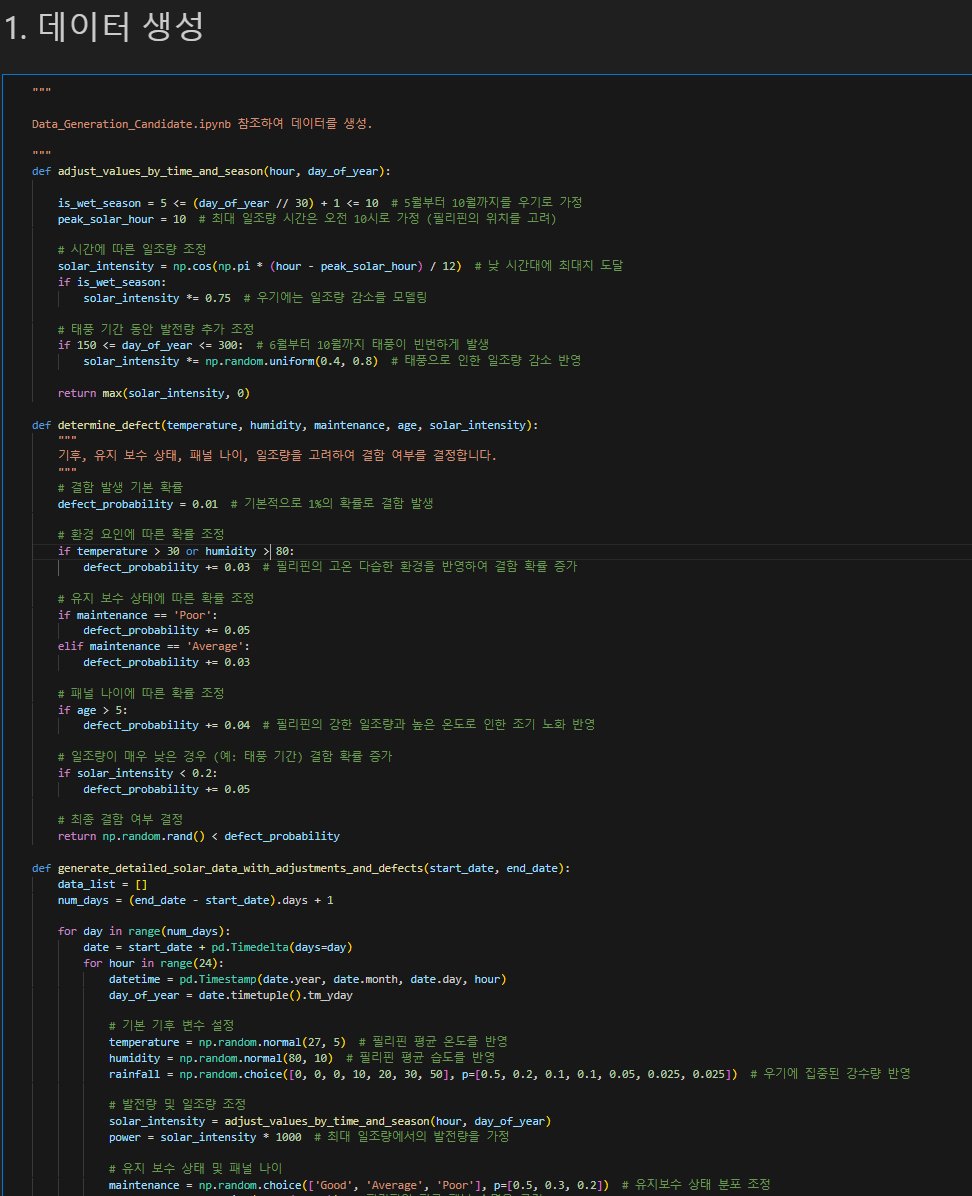
데이터생성은 Data_Generation_Candidate.ipynb 파일을 보시면 후보코드들이 있습니다.
기본 표준편차를 이용하여 생성하는 기본코드부터 밑에 사진에 포함된 예외처리를 이용한 코드들이 여러가지 있으니,
자기 자신에 맞는 상황에 따라 Customize하시면 좋을 것 같읍니다.
분석 시작
Check Data라는 함수를 만들어 예를 들면,
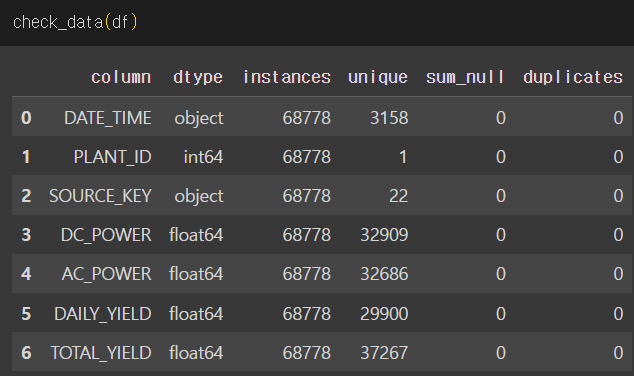
이렇게 바로 Summary를 볼 수 있게 만듭니다.
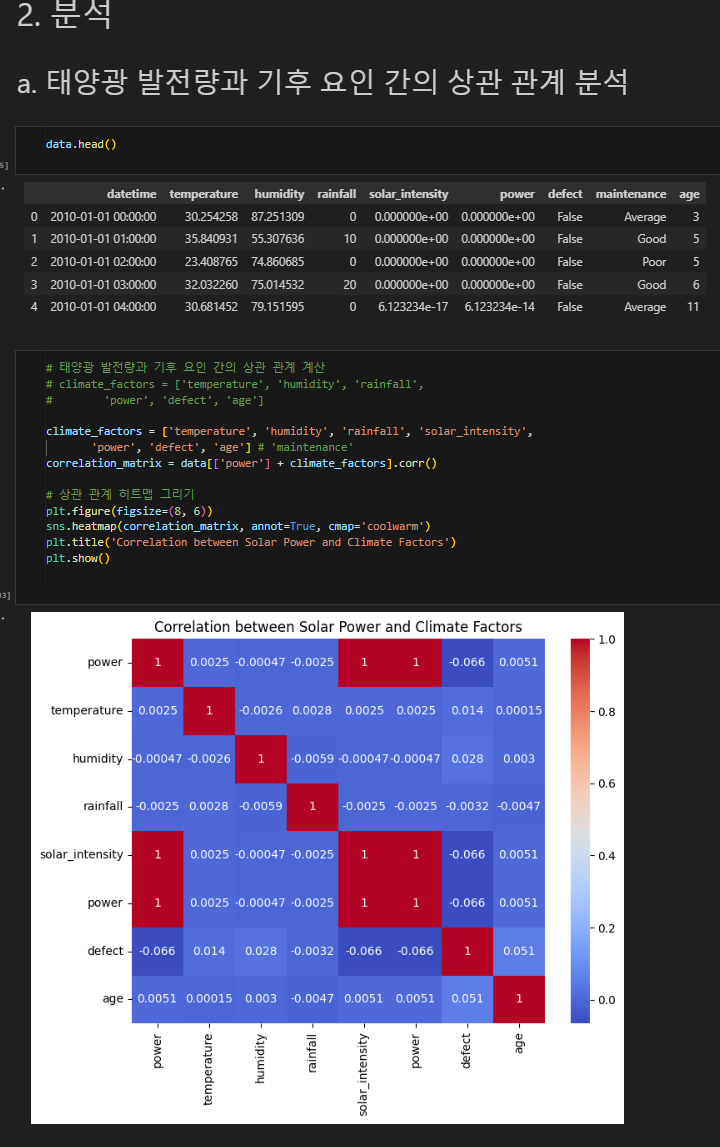
Modeling
여러가지 모델링을 통해 저는 패널의 불량 유무를 확인하는 Classification을 진행하여 Feature Importance를 뽑고 오분류표를 뽑아 얼마나 성능이 잘 나오는지를 확인하였읍니다.

↑ Modeling
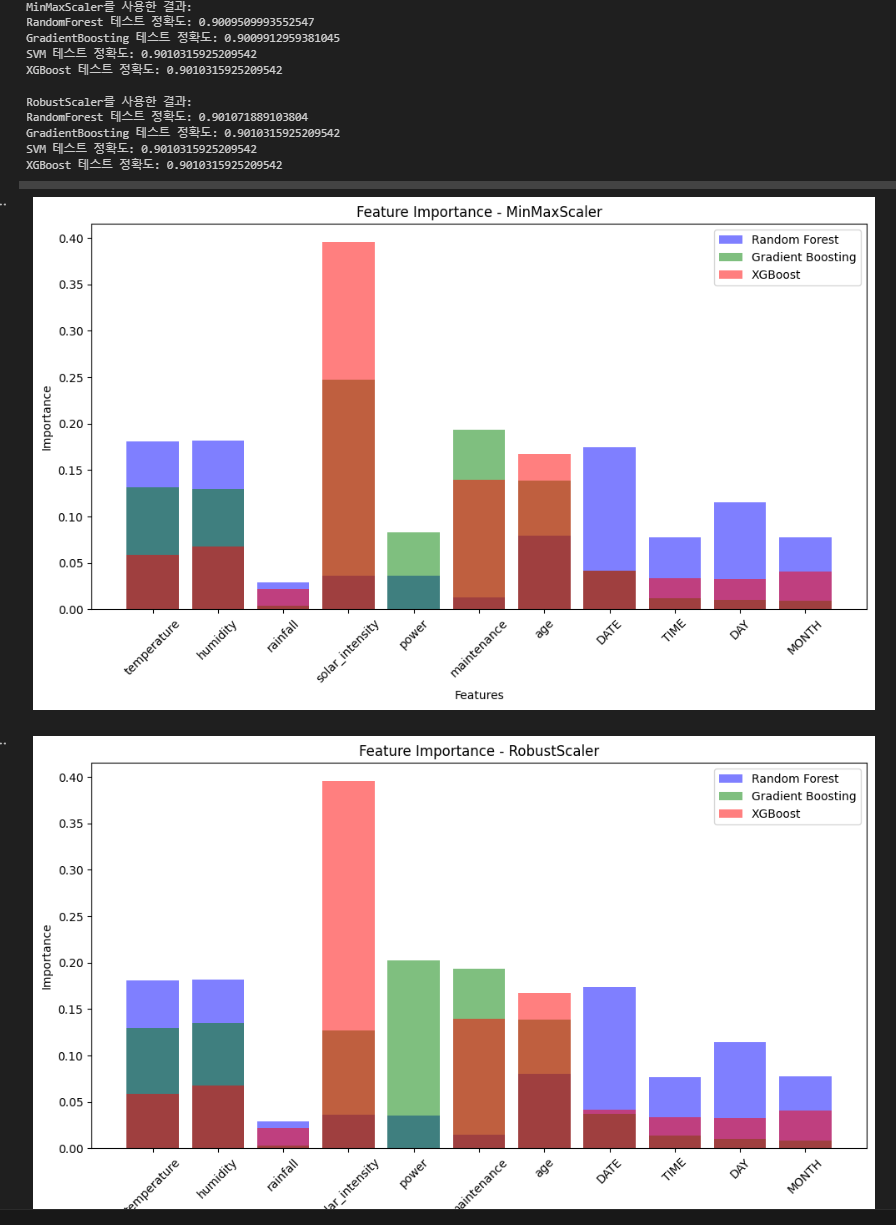
↑ Modeling Result
추후 실행 마크 다운에는 여러가지 코드들이 있으니 이것저것 좋바하여 실행 해 보시면 여러가지 공부가 될 것 같읍니다.
결과 출력 코드를 통해 오분류표(Accuracy, Recall, Precision, F1 Score)를 확인 합니다.
# 결과 출력
for result in results:
print(f"Model: {result}")
for key, value in results[result].items():
print(f"{key}: {value}")
print("\n")
# 앙상블 모델 구성 및 평가 (예시: MinMaxScaler 사용)
estimators = []
for model_name, model_info in models_params.items():
best_model = GridSearchCV(model_info['model'], model_info['params'], cv=5, scoring='accuracy').fit(X_train_minmax, y_train).best_estimator_
estimators.append((model_name, best_model))
voting_classifier = VotingClassifier(estimators=estimators, voting='soft')
voting_classifier.fit(X_train_minmax, y_train)
y_pred_ensemble = voting_classifier.predict(X_test_minmax)
# 앙상블 모델의 성능 평가
ensemble_accuracy = accuracy_score(y_test, y_pred_ensemble)
ensemble_precision = precision_score(y_test, y_pred_ensemble, average='macro')
ensemble_recall = recall_score(y_test, y_pred_ensemble, average='macro')
ensemble_f1 = f1_score(y_test, y_pred_ensemble, average='macro')
print("Ensemble Model Performance (MinMaxScaler):")
print(f"Accuracy: {ensemble_accuracy}")
print(f"Precision: {ensemble_precision}")
print(f"Recall: {ensemble_recall}")
print(f"F1 Score: {ensemble_f1}")
그리고 찾아보니 Kaggle에 실제 Panel Solar Data가 있어 링크 남겨놓을테니 필요하신분은 확인해보시면 좋을거 같읍니다. Kaggle에서 경진 데이터라 다재다능하게 분석한 유저들의 기록도 참고하시면 정말 좋을것같읍니다.
Solar Panel Analysis ☀️⚡♻️
Kaggle : https://www.kaggle.com/code/dianaddx/solar-panel-analysis
Solar Panel Analysis ☀️⚡♻️
Explore and run machine learning code with Kaggle Notebooks | Using data from Solar Power Generation Data
www.kaggle.com
파일의 오타나 궁금하신점은 tasktaeyun@gmail.com로 메일보내주시면 성심성의껏 답변 드리겠읍니다.